本文是我学习吴恩达(Andrew Ng)《Deep Learning Specialization》后整理的笔记,记录第一部分 Neural Networks and Deep Learning 的核心内容。
这一部分不再重复展开机器学习课程内容。
从单层模型到深层网络
二元分类仍然可以从逻辑回归起步。对单个样本 x∈Rnx,模型写成
z=wTx+b,a=σ(z)其中 a 表示预测为正类的概率。若训练集包含 m 个样本,更常用的写法是把所有样本按列堆成矩阵
X=[x(1)x(2)⋯x(m)]∈Rnx×m,Y=[y(1)y(2)⋯y(m)]∈R1×m这样做以后,单样本的线性计算就可以改写成整批样本的矩阵形式。这个记号在后面的神经网络里会直接延续下来。
如果只保留一层线性变换和一个 sigmoid 输出,本质上还是逻辑回归。神经网络真正发生变化的地方,在于中间开始出现多层隐藏层。输入不再直接映射到输出,而是先经过若干层中间表示,再得到最后结果。
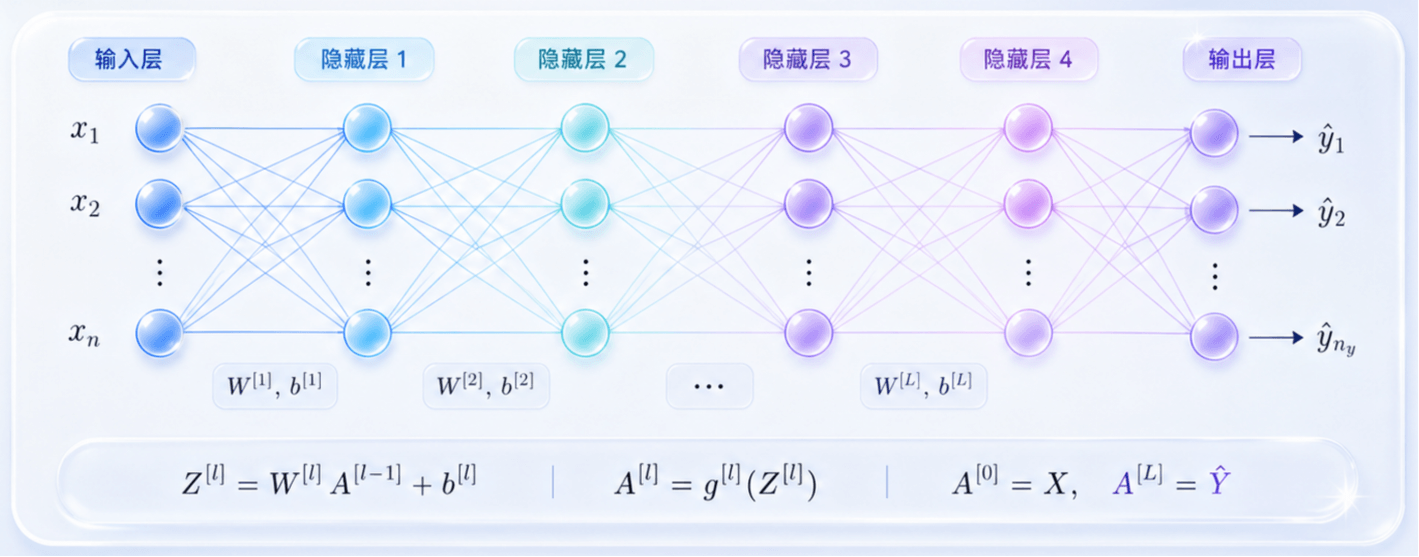
若把输入层记为第 0 层,则对第 l 层有
A[0]=XZ[l]=W[l]A[l−1]+b[l],A[l]=g[l](Z[l])这里:
- W[l] 是第 l 层的权重矩阵;
- b[l] 是第 l 层的偏置向量;
- Z[l] 是该层的线性输出;
- A[l] 是经过激活函数后的输出;
- g[l] 表示第 l 层所使用的激活函数。
对深层网络来说,最值得固定的是维度关系。若第 l 层有 n[l] 个单元,则
W[l]∈Rn[l]×n[l−1],b[l]∈Rn[l]×1Z[l],A[l]∈Rn[l]×m这个写法直接对应列表示样本,行表示该层单元。
前向传播与激活函数
神经网络的前向传播,本质上就是把上一层的输出作为下一层的输入,按层重复计算 Z[l] 和 A[l]。若网络一共有 L 层,则前向传播最终给出输出层激活 A[L]。
在二元分类中,最后一层通常仍然使用 sigmoid,于是
Y^=A[L]=σ(Z[L])如果中间层全部都只用线性函数,那么多层叠加以后仍然可以合并成一个线性变换,因此隐藏层需要非线性激活函数。课程里重点出现的激活函数主要有以下几类:
Sigmoid
σ(z)=1+e−z1它的输出落在 (0,1),因此很适合二元分类的输出层。
Tanh
tanh(z)=ez+e−zez−e−z它的输出范围是 (−1,1),在隐藏层里通常比 sigmoid 更自然一些,因为输出围绕 0 分布。
ReLU
g(z)=max(0,z)ReLU 在隐藏层中最常见。它的表达非常简单,实际实现也直接。
激活函数的导数同样要一起记住,因为反向传播会直接用到。对 sigmoid 有
σ′(z)=σ(z)(1−σ(z))对 tanh 有
dzdtanh(z)=1−tanh2(z)而 ReLU 的导数可以写成分段形式:
g′(z)={1,0,z>0z<0这里输出层按任务决定,隐藏层则主要关心非线性表示能力。
反向传播与梯度计算
如果前向传播是在计算预测值,那么反向传播就是在计算各层参数对代价函数的梯度。对深层网络来说,这部分内容的核心是统一的链式结构。
二元分类下,若代价函数写作
J=−m1i=1∑m[y(i)loga[L](i)+(1−y(i))log(1−a[L](i))]那么在 sigmoid 输出层,可以直接得到一个非常简洁的结果:
dZ[L]=A[L]−Y这一步很关键,因为它把输出层的梯度起点固定下来了。后面各层的反向传播则统一写成
dW[l]=m1dZ[l](A[l−1])Tdb[l]=m1sum(dZ[l], axis=1, keepdims=True)dA[l−1]=(W[l])TdZ[l]dZ[l−1]=dA[l−1]⊙g[l−1]′(Z[l−1])其中:
- dZ[l] 表示代价函数对第 l 层线性输出的导数;
- dW[l]、db[l] 是对参数的梯度;
- dA[l−1] 把梯度继续传回前一层;
- ⊙ 表示按元素相乘。
这些式子连起来以后,就形成了一个统一模板:
- 先由输出层得到 dZ[L];
- 再逐层向后计算 dW[l]、db[l];
- 同时把梯度通过 dA[l−1] 继续传回去;
- 最终得到所有层参数的梯度。
和前面机器学习里的梯度下降相比,这里真正新增的是多层结构下的链式传递,而不是“梯度下降”这件事本身。
对实现而言,前向传播和反向传播通常会写成模块化结构。一个常见的基本单元是:
LINEAR:计算 Z=WA+b;LINEAR -> ACTIVATION:再接一个激活函数得到 A;- 最后把若干个这样的模块按顺序堆起来。
这样做以后,深层网络就不需要为每一层单独重写一遍公式,前向和反向都可以围绕同一套模块展开。
向量化与实现中的维度问题
如果不向量化,那么每一层都要对每个样本分别计算一次前向传播和反向传播;一旦样本数变大,写法和效率都会变得很差。改成矩阵形式以后,同一层对 m 个样本的计算可以一次完成,这也是为什么前面始终把样本按列堆到一起。
这一点在深层网络里尤其容易体现在 shape 上。假设共有 m 个样本,则:
- 输入矩阵 X 的形状是 (n[0],m);
- 第 l 层激活 A[l] 的形状是 (n[l],m);
- 第 l 层参数 W[l] 的形状是 (n[l],n[l−1]);
- 偏置 b[l] 的形状是 (n[l],1)。
其中偏置会借助广播机制自动扩展到 (n[l],m)。这一点在 NumPy 里很常见,但前提是形状必须写对。
Python 广播和向量化本身并不是深度学习专属内容,不过在神经网络实现里,它们已经成为默认前提。课程中反复强调 shape,原因也在这里:很多实现错误并不是公式错了,而是数组形状没有保持一致。
深层网络的训练方式
有了前向传播和反向传播之后,训练过程就可以写得很简洁。若把全部参数记成
{W[1],b[1],W[2],b[2],…,W[L],b[L]}那么一次完整训练迭代通常包含四步:
- 前向传播,得到各层 Z[l] 和 A[l];
- 计算代价函数 J;
- 反向传播,得到所有梯度;
- 用梯度下降更新参数。
更新式仍然是
W[l]:=W[l]−αdW[l],b[l]:=b[l]−αdb[l]其中 α 是学习率。梯度来自反向传播,并且每一层都有自己的一组参数与梯度。
对于参数和超参数,参数是训练过程中被学习出来的量,例如各层的 W[l] 和 b[l];超参数则是在训练开始前人为设定的量,例如:
- 学习率 α;
- 层数 L;
- 每层单元数 n[l];
- 激活函数的选择;
- 训练迭代次数。
对深层网络来说,超参数开始显著增多,这也意味着模型设计不再只是写出一个损失函数那么简单,而是需要同时考虑网络结构本身。
随机初始化与深层表示
深层网络训练时,参数不能全部初始化为 0。如果某一层的所有权重从一开始都完全相同,那么这些单元在前向传播中会得到相同输出,在反向传播中也会得到相同梯度,最后始终保持一致,等价于这一层实际上只有一个单元。随机初始化正是用来打破这种对称性。
常见写法是让权重从较小的随机数开始,例如
W[l]∼small random values,b[l]=0偏置初始化为 0 往往没有问题,因为真正需要打破对称的是权重矩阵。
至于为什么网络要做深,实际上浅层网络当然也能表示函数,但深层网络更容易逐层形成中间表示。前面的层先提取较简单的结构,后面的层再在这些结构上继续组合。放到图像任务里,低层特征可以对应边缘、局部纹理和简单形状,更高层则逐渐对应到更完整的局部模式和整体目标。