本文是我学习吴恩达(Andrew Ng)《Machine Learning Specialization》(2022)后整理的笔记,覆盖 Part 1:Supervised Machine Learning: Regression and Classification 。
机器学习的分类 机器学习任务按是否存在标签(label)划分为监督学习(Supervised Learning)与非监督学习(Unsupervised Learning)。
Machine Learning Supervised Learning(监督学习) Regression(回归) :输出连续数值Classification(分类) :输出离散类别(可为二分类或多分类)Unsupervised Learning(非监督学习) Clustering(聚类) (Google News 新闻聚类,DNA microarray,Grouping customers)Anomaly Detection(异常检测) Dimensionality Reduction(降维) 基本线性回归模型 代价函数 在线性回归中,预测函数写作
f w , b ( x ) = w x + b f_{w,b}(x)=wx+b f w , b ( x ) = w x + b 其中 w , b w,b w , b x x x i i i ( x ( i ) , y ( i ) ) (x^{(i)}, y^{(i)}) ( x ( i ) , y ( i ) )
y ^ ( i ) = f w , b ( x ( i ) ) \hat y^{(i)} = f_{w,b}(x^{(i)}) y ^ ( i ) = f w , b ( x ( i ) ) 训练问题的核心并不是给出一条“看起来合适”的直线,而是用统一标准衡量参数 ( w , b ) (w,b) ( w , b )
J ( w , b ) = 1 2 m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) 2 = 1 2 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) 2 J(w,b)=\frac{1}{2m}\sum_{i=1}^{m}\left(\hat y^{(i)}-y^{(i)}\right)^2 =\frac{1}{2m}\sum_{i=1}^{m}\left(f_{w,b}(x^{(i)})-y^{(i)}\right)^2 J ( w , b ) = 2 m 1 i = 1 ∑ m ( y ^ ( i ) − y ( i ) ) 2 = 2 m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) 2 这里 m m m
min w , b J ( w , b ) \min_{w,b} J(w,b) w , b min J ( w , b ) 到这一步为止,线性回归训练已经被完整表述为一个优化问题:参数 ( w , b ) (w,b) ( w , b ) x ( i ) x^{(i)} x ( i ) y ( i ) y^{(i)} y ( i ) y ^ ( i ) \hat y^{(i)} y ^ ( i ) m m m f w , b ( x ) f_{w,b}(x) f w , b ( x ) J ( w , b ) J(w,b) J ( w , b )
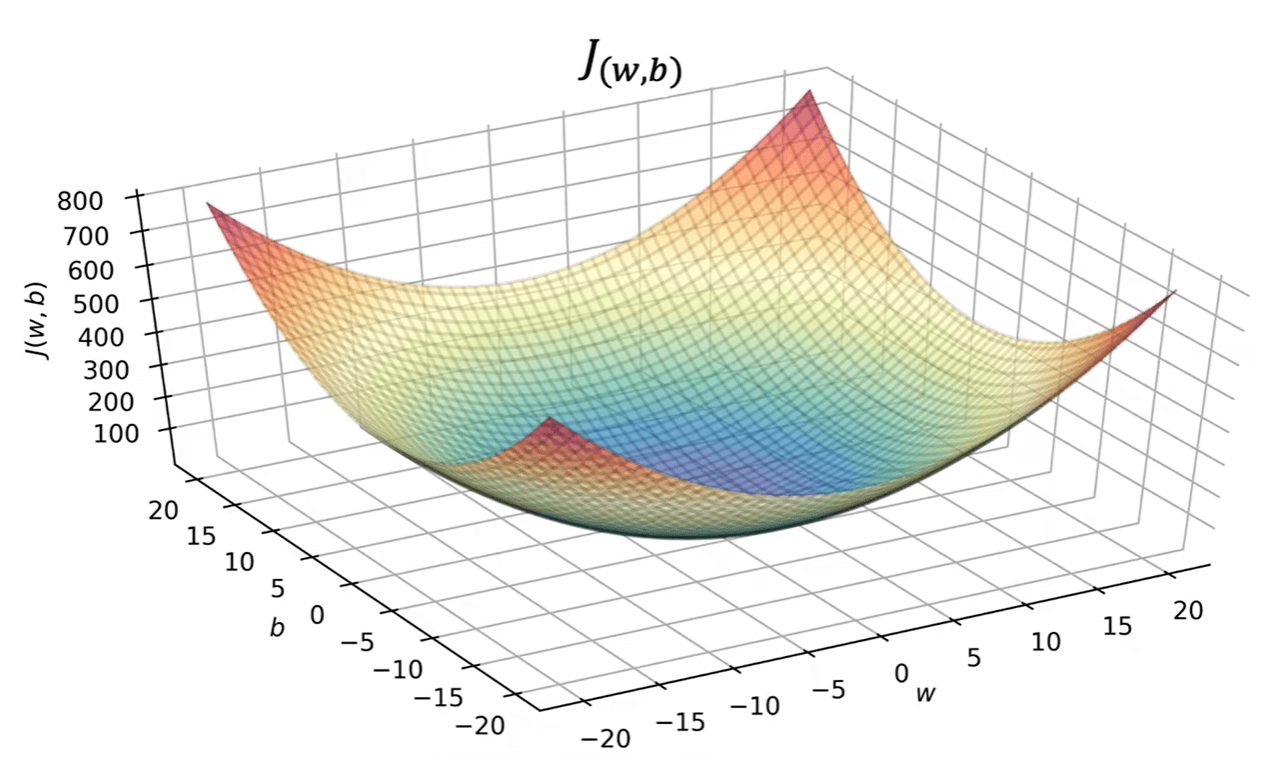
在参数空间中观察 J ( w , b ) J(w,b) J ( w , b )
梯度下降 梯度下降(Gradient Descent)是一个通用优化方法,用于最小化目标函数。在当前场景中,它作用于 J ( w , b ) J(w,b) J ( w , b )
在线性回归的双参数形式下,梯度下降写作:
repeat until convergence { w = w − α ∂ ∂ w J ( w , b ) b = b − α ∂ ∂ b J ( w , b ) \text{repeat until convergence } \left\{ \begin{aligned} w &= w-\alpha \frac{\partial}{\partial w}J(w,b) \\\\ b &= b-\alpha \frac{\partial}{\partial b}J(w,b) \end{aligned} \right. repeat until convergence ⎩ ⎨ ⎧ w b = w − α ∂ w ∂ J ( w , b ) = b − α ∂ b ∂ J ( w , b ) 其中 α \alpha α
w = w − α d d w J ( w ) w = w-\alpha \frac{d}{dw}J(w) w = w − α d w d J ( w ) 则更新方向更容易理解:导数为正时参数减小,导数为负时参数增大,更新方向始终朝向使目标函数下降的一侧。接近最小值时导数变小,更新步长也会自然变小,因此在不少情况下即使 α \alpha α
学习率的作用需要单独保留:α \alpha α α \alpha α
将线性回归模型代入代价函数后,可得到梯度下降所需的具体偏导数。记
J ( w , b ) = 1 2 m ∑ i = 1 m ( w x ( i ) + b − y ( i ) ) 2 J(w,b)=\frac{1}{2m}\sum_{i=1}^{m}\left(wx^{(i)}+b-y^{(i)}\right)^2 J ( w , b ) = 2 m 1 i = 1 ∑ m ( w x ( i ) + b − y ( i ) ) 2 则有
∂ ∂ w J ( w , b ) = 1 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) x ( i ) \frac{\partial}{\partial w}J(w,b)=\frac{1}{m}\sum_{i=1}^{m}\left(f_{w,b}(x^{(i)})-y^{(i)}\right)x^{(i)} ∂ w ∂ J ( w , b ) = m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) x ( i ) ∂ ∂ b J ( w , b ) = 1 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) \frac{\partial}{\partial b}J(w,b)=\frac{1}{m}\sum_{i=1}^{m}\left(f_{w,b}(x^{(i)})-y^{(i)}\right) ∂ b ∂ J ( w , b ) = m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) 代回更新式后,线性回归的梯度下降形式为
repeat until convergence { w = w − α ⋅ 1 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) x ( i ) b = b − α ⋅ 1 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) \text{repeat until convergence } \left\{ \begin{aligned} w &= w-\alpha \cdot \frac{1}{m}\sum_{i=1}^{m}\left(f_{w,b}(x^{(i)})-y^{(i)}\right)x^{(i)} \\\\ b &= b-\alpha \cdot \frac{1}{m}\sum_{i=1}^{m}\left(f_{w,b}(x^{(i)})-y^{(i)}\right) \end{aligned} \right. repeat until convergence ⎩ ⎨ ⎧ w b = w − α ⋅ m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) x ( i ) = b − α ⋅ m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) 每一步更新都使用全部训练样本,因此这里对应的是 Batch Gradient Descent 。这一点在本阶段主要是计算方式上的确认:参数更新基于整批数据,而不是部分样本。
这一部分最容易出错的地方并不在推导,而在更新顺序。理论表达要求 w w w b b b
参数空间中的下降过程、数据空间中的拟合直线变化以及代价函数值的下降,本质上是同一过程在不同表示下的对应。在线性回归的平方误差代价函数场景中,目标函数呈碗形(bowl shape)并具有凸性(convexity),因此优化过程的几何结构相对清晰,这也使它成为理解梯度下降的合适起点。
多类特征线性回归 向量化 当输入不再是单一特征 x x x x 1 , … , x n x_1,\dots,x_n x 1 , … , x n ( x ⃗ ( i ) , y ( i ) ) (\vec{x}^{(i)}, y^{(i)}) ( x ( i ) , y ( i ) ) x ⃗ ( i ) = [ x 1 ( i ) , x 2 ( i ) , … , x n ( i ) ] \vec{x}^{(i)}=[x_1^{(i)},x_2^{(i)},\dots,x_n^{(i)}] x ( i ) = [ x 1 ( i ) , x 2 ( i ) , … , x n ( i ) ]
f w ⃗ , b ( x ⃗ ) = w 1 x 1 + w 2 x 2 + ⋯ + w n x n + b f_{\vec{w},b}(\vec{x}) = w_1x_1+w_2x_2+\cdots+w_nx_n+b f w , b ( x ) = w 1 x 1 + w 2 x 2 + ⋯ + w n x n + b 也常写为点积形式
f w ⃗ , b ( x ⃗ ) = w ⃗ ⋅ x ⃗ + b f_{\vec{w},b}(\vec{x}) = \vec{w}\cdot \vec{x} + b f w , b ( x ) = w ⋅ x + b 这里 w ⃗ = [ w 1 , … , w n ] \vec{w}=[w_1,\dots,w_n] w = [ w 1 , … , w n ] multiple linear regression (多个输入特征),与“多个输出”的 multivariate regression 区分。
在多特征场景中,向量化(vectorization)主要用于把“逐维求和/逐维更新”写成向量运算,从而使预测与参数更新都能以统一形式表达。对单个样本的预测可以写为 y ^ ( i ) = f w ⃗ , b ( x ⃗ ( i ) ) \hat y^{(i)}=f_{\vec{w},b}(\vec{x}^{(i)}) y ^ ( i ) = f w , b ( x ( i ) ) dot(w, x) + b。数学记号通常以 j = 1 , … , n j=1,\dots,n j = 1 , … , n 0 0 0
多特征下的平方误差代价函数保持同一结构,只是把模型替换为 f w ⃗ , b f_{\vec{w},b} f w , b
J ( w ⃗ , b ) = 1 2 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) 2 J(\vec{w},b)=\frac{1}{2m}\sum_{i=1}^{m}\left(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}\right)^2 J ( w , b ) = 2 m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) 2 训练目标写作
min w ⃗ , b J ( w ⃗ , b ) \min_{\vec{w},b} J(\vec{w},b) w , b min J ( w , b ) 多元线性回归的梯度下降 梯度下降从单变量的 ( w , b ) (w,b) ( w , b ) ( w 1 , … , w n , b ) (w_1,\dots,w_n,b) ( w 1 , … , w n , b )
repeat until convergence { w j = w j − α ∂ ∂ w j J ( w ⃗ , b ) ( j = 1 , … , n ) b = b − α ∂ ∂ b J ( w ⃗ , b ) \text{repeat until convergence } \left\{ \begin{aligned} w_j &= w_j-\alpha \frac{\partial}{\partial w_j}J(\vec{w},b)\quad (j=1,\dots,n) \\\\ b &= b-\alpha \frac{\partial}{\partial b}J(\vec{w},b) \end{aligned} \right. repeat until convergence ⎩ ⎨ ⎧ w j b = w j − α ∂ w j ∂ J ( w , b ) ( j = 1 , … , n ) = b − α ∂ b ∂ J ( w , b ) 其中 α \alpha α
∂ ∂ w j J ( w ⃗ , b ) = 1 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) x j ( i ) \frac{\partial}{\partial w_j}J(\vec{w},b)=\frac{1}{m}\sum_{i=1}^{m}\left(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}\right)x_j^{(i)} ∂ w j ∂ J ( w , b ) = m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) x j ( i ) ∂ ∂ b J ( w ⃗ , b ) = 1 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) \frac{\partial}{\partial b}J(\vec{w},b)=\frac{1}{m}\sum_{i=1}^{m}\left(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}\right) ∂ b ∂ J ( w , b ) = m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) 代回后得到显式更新式:
repeat until convergence { w j = w j − α ⋅ 1 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) x j ( i ) b = b − α ⋅ 1 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) \text{repeat until convergence } \left\{ \begin{aligned} w_j &= w_j-\alpha \cdot \frac{1}{m}\sum_{i=1}^{m}\left(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}\right)x_j^{(i)} \\\\ b &= b-\alpha \cdot \frac{1}{m}\sum_{i=1}^{m}\left(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}\right) \end{aligned} \right. repeat until convergence ⎩ ⎨ ⎧ w j b = w j − α ⋅ m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) x j ( i ) = b − α ⋅ m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) 每一步更新都遍历所有训练样本,因此对应 Batch Gradient Descent 。实现时需要 simultaneously update :同一轮迭代中先基于旧的参数计算所有 w j w_j w j b b b
参数更新也可以写成向量形式:若记梯度向量 d ⃗ = [ ∂ ∂ w 1 J , … , ∂ ∂ w n J ] \vec{d}=[\frac{\partial}{\partial w_1}J,\dots,\frac{\partial}{\partial w_n}J] d = [ ∂ w 1 ∂ J , … , ∂ w n ∂ J ]
w ⃗ : = w ⃗ − α d ⃗ \vec{w} := \vec{w}-\alpha \vec{d} w := w − α d 这对应实现中用向量运算替代逐维循环更新。
特征缩放 多特征回归中,特征尺度差异会直接影响梯度下降的迭代表现。常见目标是把各特征调整到相近范围(例如接近 [ − 1 , 1 ] [-1,1] [ − 1 , 1 ] [ − 3 , 3 ] [-3,3] [ − 3 , 3 ]
Mean normalization:
x j , scaled = x j − μ j x j , max − x j , min x_{j,\text{scaled}}=\frac{x_j-\mu_j}{x_{j,\max}-x_{j,\min}} x j , scaled = x j , m a x − x j , m i n x j − μ j Z-score normalization:
x j , scaled = x j − μ j σ j x_{j,\text{scaled}}=\frac{x_j-\mu_j}{\sigma_j} x j , scaled = σ j x j − μ j 其中 μ j \mu_j μ j j j j σ j \sigma_j σ j
检查收敛与学习率选择 梯度下降的常用收敛检查方式是观察 J ( w ⃗ , b ) J(\vec{w},b) J ( w , b ) ε \varepsilon ε ε \varepsilon ε
学习率 α \alpha α J ( w ⃗ , b ) J(\vec{w},b) J ( w , b ) α \alpha α α \alpha α
… , 0.001 , 0.003 , 0.01 , 0.03 , 0.1 , 0.3 , 1 , … \dots,\,0.001,\,0.003,\,0.01,\,0.03,\,0.1,\,0.3,\,1,\,\dots … , 0.001 , 0.003 , 0.01 , 0.03 , 0.1 , 0.3 , 1 , … 在多特征场景下,特征缩放往往决定了“可用学习率区间”的宽窄:未缩放时即使取很小的 α \alpha α
特征工程与多项式回归 在保持线性回归训练框架(代价函数 + 梯度下降)不变的前提下,扩展模型表达能力通常通过构造新特征完成。典型的特征工程包括构造交互项,例如
x 3 = x 1 x 2 x_3=x_1x_2 x 3 = x 1 x 2 将模型扩展为 f w ⃗ , b ( x ⃗ ) = w 1 x 1 + w 2 x 2 + w 3 x 3 + b f_{\vec{w},b}(\vec{x})=w_1x_1+w_2x_2+w_3x_3+b f w , b ( x ) = w 1 x 1 + w 2 x 2 + w 3 x 3 + b
多项式回归可以视为把单一变量 x x x x , x 2 , x 3 x,x^2,x^3 x , x 2 , x 3
f w ⃗ , b ( x ) = w 1 x + w 2 x 2 + w 3 x 3 + b f_{\vec{w},b}(x)=w_1x+w_2x^2+w_3x^3+b f w , b ( x ) = w 1 x + w 2 x 2 + w 3 x 3 + b 由于高阶项会显著改变数值范围,多项式特征通常需要配合特征缩放,以保证梯度下降在更新时数值稳定、收敛过程可控。
到这里,多特征线性回归的训练流程可以被固定为一组一致的要素:以 x ⃗ \vec{x} x f w ⃗ , b f_{\vec{w},b} f w , b J ( w ⃗ , b ) J(\vec{w},b) J ( w , b )
Logistic 回归 前面线性回归的目标是预测连续值;当任务切换到二分类时,标签 y ∈ { 0 , 1 } y\in\{0,1\} y ∈ { 0 , 1 } [ 0 , 1 ] [0,1] [ 0 , 1 ] x ⃗ , w ⃗ , b \vec{x},\vec{w},b x , w , b
先定义线性部分
z = w ⃗ ⋅ x ⃗ + b z=\vec{w}\cdot\vec{x}+b z = w ⋅ x + b sigmoid 函数为
g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g ( z ) = 1 + e − z 1 逻辑回归模型写作
f w ⃗ , b ( x ⃗ ) = g ( w ⃗ ⋅ x ⃗ + b ) = 1 1 + e − ( w ⃗ ⋅ x ⃗ + b ) f_{\vec{w},b}(\vec{x})=g(\vec{w}\cdot\vec{x}+b) =\frac{1}{1+e^{-(\vec{w}\cdot\vec{x}+b)}} f w , b ( x ) = g ( w ⋅ x + b ) = 1 + e − ( w ⋅ x + b ) 1 并记作
f w ⃗ , b ( x ⃗ ) = P ( y = 1 ∣ x ⃗ ; w ⃗ , b ) , P ( y = 0 ∣ x ⃗ ; w ⃗ , b ) = 1 − f w ⃗ , b ( x ⃗ ) f_{\vec{w},b}(\vec{x}) = P(y=1\mid \vec{x};\vec{w},b),\qquad P(y=0\mid \vec{x};\vec{w},b)=1-f_{\vec{w},b}(\vec{x}) f w , b ( x ) = P ( y = 1 ∣ x ; w , b ) , P ( y = 0 ∣ x ; w , b ) = 1 − f w , b ( x ) 在预测规则上,常用阈值 0.5 0.5 0.5 f w ⃗ , b ( x ⃗ ) ≥ 0.5 f_{\vec{w},b}(\vec{x})\ge 0.5 f w , b ( x ) ≥ 0.5 y ^ = 1 \hat y=1 y ^ = 1 y ^ = 0 \hat y=0 y ^ = 0 g ( z ) g(z) g ( z )
f w ⃗ , b ( x ⃗ ) ≥ 0.5 ⟺ z ≥ 0 ⟺ w ⃗ ⋅ x ⃗ + b ≥ 0 f_{\vec{w},b}(\vec{x})\ge 0.5 \Longleftrightarrow z\ge 0 \Longleftrightarrow \vec{w}\cdot\vec{x}+b\ge 0 f w , b ( x ) ≥ 0.5 ⟺ z ≥ 0 ⟺ w ⋅ x + b ≥ 0 因此决策边界(decision boundary)由
w ⃗ ⋅ x ⃗ + b = 0 \vec{w}\cdot\vec{x}+b=0 w ⋅ x + b = 0 给出。需要强调的是:决策边界由 z = 0 z=0 z = 0 z = 0 z=0 z = 0
逻辑回归的代价函数 逻辑回归的训练依旧写成最小化代价函数 J J J ( x ⃗ ( i ) , y ( i ) ) (\vec{x}^{(i)},y^{(i)}) ( x ( i ) , y ( i ) )
L ( f w ⃗ , b ( x ⃗ ( i ) ) , y ( i ) ) = { − log ( f w ⃗ , b ( x ⃗ ( i ) ) ) , y ( i ) = 1 − log ( 1 − f w ⃗ , b ( x ⃗ ( i ) ) ) , y ( i ) = 0 L\big(f_{\vec{w},b}(\vec{x}^{(i)}),y^{(i)}\big)= \begin{cases} -\log\big(f_{\vec{w},b}(\vec{x}^{(i)})\big), & y^{(i)}=1\\[4pt] -\log\big(1-f_{\vec{w},b}(\vec{x}^{(i)})\big), & y^{(i)}=0 \end{cases} L ( f w , b ( x ( i ) ) , y ( i ) ) = { − log ( f w , b ( x ( i ) ) ) , − log ( 1 − f w , b ( x ( i ) ) ) , y ( i ) = 1 y ( i ) = 0 常用的合并写法为
L ( f w ⃗ , b ( x ⃗ ( i ) ) , y ( i ) ) = − y ( i ) log ( f w ⃗ , b ( x ⃗ ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − f w ⃗ , b ( x ⃗ ( i ) ) ) L\big(f_{\vec{w},b}(\vec{x}^{(i)}),y^{(i)}\big) = -\,y^{(i)}\log\big(f_{\vec{w},b}(\vec{x}^{(i)})\big) -\big(1-y^{(i)}\big)\log\big(1-f_{\vec{w},b}(\vec{x}^{(i)})\big) L ( f w , b ( x ( i ) ) , y ( i ) ) = − y ( i ) log ( f w , b ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − f w , b ( x ( i ) ) ) 总体代价函数取平均:
J ( w ⃗ , b ) = 1 m ∑ i = 1 m L ( f w ⃗ , b ( x ⃗ ( i ) ) , y ( i ) ) J(\vec{w},b)=\frac{1}{m}\sum_{i=1}^{m}L\big(f_{\vec{w},b}(\vec{x}^{(i)}),y^{(i)}\big) J ( w , b ) = m 1 i = 1 ∑ m L ( f w , b ( x ( i ) ) , y ( i ) ) 至此可以看到,分类并没有改变“训练范式”:仍然是通过选择 f f f J J J J J J
正则化 当特征数量增多,或引入更复杂的特征(例如高次项、交互项)时,模型容易出现过拟合(overfitting / high variance):训练集拟合很好,但泛化变差。常见的处理路径包括增加训练样本、特征选择与正则化。这里正则化的写法非常“干净”:不改变模型形式,而是在代价函数里加入对参数规模的惩罚项,从而让学习过程倾向于较小的参数。
常用 L 2 L2 L 2 b b b
λ 2 m ∑ j = 1 n w j 2 \frac{\lambda}{2m}\sum_{j=1}^{n}w_j^2 2 m λ j = 1 ∑ n w j 2 其中 λ \lambda λ
正则化代价函数 线性回归的正则化代价函数写作
J ( w ⃗ , b ) = 1 2 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) 2 + λ 2 m ∑ j = 1 n w j 2 J(\vec{w},b)=\frac{1}{2m}\sum_{i=1}^{m}\big(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}\big)^2 +\frac{\lambda}{2m}\sum_{j=1}^{n}w_j^2 J ( w , b ) = 2 m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) 2 + 2 m λ j = 1 ∑ n w j 2 逻辑回归的正则化代价函数为
J ( w ⃗ , b ) = − 1 m ∑ i = 1 m [ y ( i ) log ( f w ⃗ , b ( x ⃗ ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − f w ⃗ , b ( x ⃗ ( i ) ) ) ] + λ 2 m ∑ j = 1 n w j 2 J(\vec{w},b)= -\frac{1}{m}\sum_{i=1}^{m}\left[ y^{(i)}\log\big(f_{\vec{w},b}(\vec{x}^{(i)})\big) +\big(1-y^{(i)}\big)\log\big(1-f_{\vec{w},b}(\vec{x}^{(i)})\big) \right] +\frac{\lambda}{2m}\sum_{j=1}^{n}w_j^2 J ( w , b ) = − m 1 i = 1 ∑ m [ y ( i ) log ( f w , b ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − f w , b ( x ( i ) ) ) ] + 2 m λ j = 1 ∑ n w j 2 梯度下降更新 在梯度下降中,以线性回归为例,正则化项直接进入 w j w_j w j j = 1 , … , n j=1,\dots,n j = 1 , … , n
w j : = w j − α [ 1 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) x j ( i ) + λ m w j ] w_j := w_j-\alpha\left[\frac{1}{m}\sum_{i=1}^{m}\big(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}\big)x_j^{(i)}+\frac{\lambda}{m}w_j\right] w j := w j − α [ m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) x j ( i ) + m λ w j ] 而 b b b
b : = b − α ⋅ 1 m ∑ i = 1 m ( f w ⃗ , b ( x ⃗ ( i ) ) − y ( i ) ) b := b-\alpha\cdot \frac{1}{m}\sum_{i=1}^{m}\big(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)}\big) b := b − α ⋅ m 1 i = 1 ∑ m ( f w , b ( x ( i ) ) − y ( i ) ) 逻辑回归的正则化训练可用同一思路理解:目标函数从未正则化的 J ( w ⃗ , b ) J(\vec{w},b) J ( w , b ) λ \lambda λ J ( w ⃗ , b ) J(\vec{w},b) J ( w , b ) w j w_j w j
总结 这一部分内容最终可以整理为同一套写法在不同任务上的复用:回归与分类的差异集中体现在 f f f J J J J J J J J J