本文是我学习吴恩达(Andrew Ng)《Machine Learning Specialization》(2022)后整理的笔记,覆盖 Part 2:Advanced Learning Algorithms。
神经元、概率输出与应用场景
神经网络最基本的计算单元可以写成线性组合后接一个非线性函数。在二分类任务里,输出常被解释为概率,因此最先出现的激活函数通常是 sigmoid:
若输入写成多特征向量 ,对应的线性部分记为
这里 是权重向量, 是偏置, 只是激活函数之前的线性输出。经过 sigmoid 之后,得到
当这个输出被理解为正类概率时,也可记成
于是一个神经元在二分类中的计算就分成了两步:先用输入得到线性打分,再把这个打分压到 到 之间。阈值判断是在这一步之后完成的,因此它属于输出解释,而不属于神经元内部的计算形式。
这一写法与前一篇中的 logistic 回归直接相连,只是这里不再停留在单个模型上,而是把它作为后续搭建更大网络的基本单元。
应用层面的例子主要有两类。一类是需求预测:价格、营销、运输成本、材料等特征共同决定某个商品是否更可能成为 top seller;另一类是图像识别:一张灰度图输入后可以被展平成高维向量 ,例如 的图像会对应到约 维输入。任务对象虽然差别很大,写成计算过程以后形式却保持一致:输入先进入线性部分,再经过激活函数得到输出。
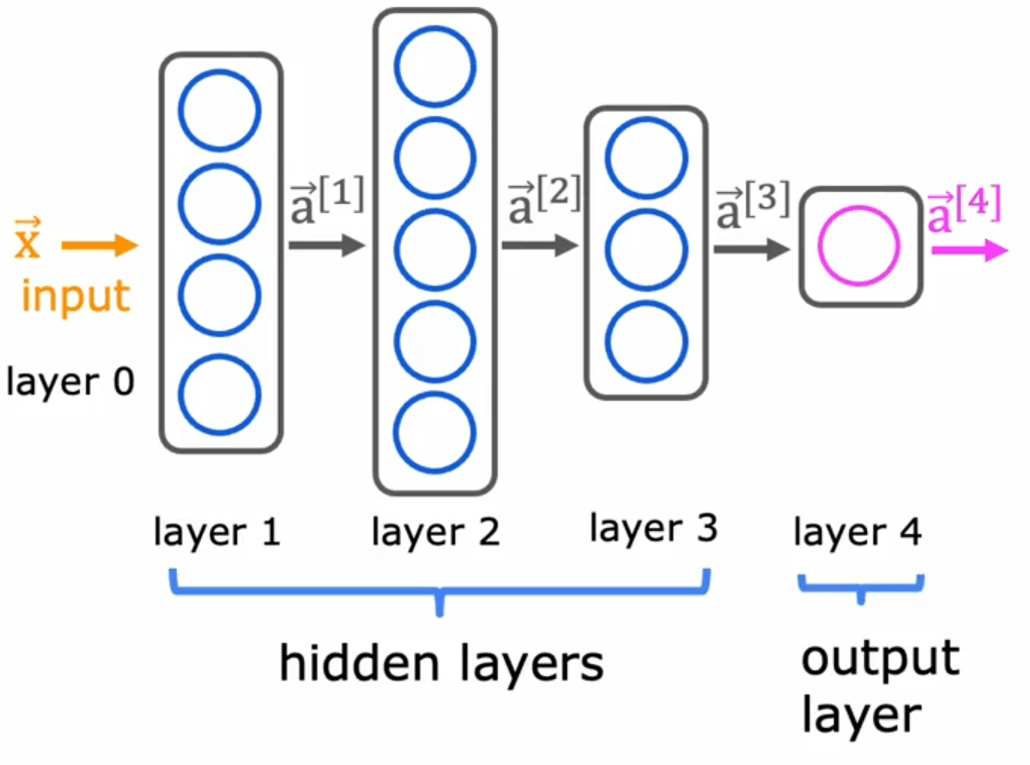
神经网络
为了统一后续记号,输入层通常写作
这里上标 表示第 层, 表示该层全部神经元的激活值。若看第 层第 个神经元,它的输出写成
也可以把线性部分单独记出来:
前一个式子给出的是该神经元最终的激活值,后一个式子把计算拆成了线性项 与激活值 两步。记号一旦分开,后面写前向传播、损失函数或反向传播时会清楚很多。
同一层里所有神经元的输出组合起来,就构成该层的激活向量。因此,网络的结构可以概括为
输入层只是计算起点;隐藏层负责逐层形成中间表示;输出层给出最终结果。在二分类里,输出层常常只有一个标量 ;若任务变成多分类或更复杂的预测,输出层的维度也会随之改变。
这里最容易混淆的是输入对象的层级。单个神经元面对的输入,并不是某一个标量,而是上一层的整个激活向量。因此,权重自然要写成向量 ,而不是一个单独的数。这一点在实现里常常会与 shape 的理解缠在一起。
前向传播
神经网络的推理过程就是前向传播。输入从 开始,沿着网络一层一层向后计算;每到一层,先得到线性项,再得到激活值。写成统一形式,就是不断重复
如果网络只有一个隐藏层,那么前向传播的顺序就是:输入 先产生 ,再由 产生 ,最后由输出层给出预测结果。每一层都只依赖前一层的输出,因此整条计算链天然是单向展开的。
把这种层间关系写进代码里,形式会很直观:
a1 = layer_1(x)a2 = layer_2(a1)a3 = layer_3(a2)这里最值得注意的不是语法本身,而是对象关系:后一层接收的输入,正是前一层的输出。代码里的 a1、a2、a3 与公式中的 、、 是一一对应的。二分类中如果需要最终标签,通常还会在最后一步再加上阈值判断;那属于输出解释的问题,不属于前向传播本身。
向量、张量与 shape
神经网络一旦进入实现层面,最容易出问题的地方往往不是公式,而是数据形状。数学上写成向量的 ,在 NumPy 或 TensorFlow 中并不一定总以同一种数组形式出现。以两个特征为例:
np.array([200, 17])是一维数组;np.array([[200, 17]])的形状是 ;np.array([[200],[17]])的形状是 。
三者数值看起来接近,但在线性代数运算和框架接口中并不等价。对神经网络来说,单样本常见写法是 ,一批样本常见写法是 。这里的含义很固定:行表示样本,列表示特征,或者表示某一层中的单元数。只要这个约定不乱,层与层之间的输入输出关系就会清楚很多。
在 TensorFlow/Keras 中,数据通常以 tf.Tensor 表示,并带有 shape 与 dtype。调试时更有效的做法通常不是逐元素检查,而是先确认 tensor.shape 是否与预期一致;必要时再用 .numpy() 把张量转成 NumPy 数组查看具体数值。很多实现错误最后追溯下来,真正的问题往往是数组维度没有对齐。
矩阵化写法
如果同一层有多个神经元,在实现上更常见的写法是把整层一次算完。设输入激活矩阵为 ,权重矩阵为 ,偏置为 ,则一层的输出可写成
这里 表示该层所有神经元在线性部分的输出, 表示这一层全部神经元的激活值。若
则有
也就是说, 个样本输入这一层后,会得到 行输出;而这一层包含多少个单元,就会对应多少列。偏置 通常写成 ,再按行广播到所有样本。
矩阵化写法的作用,是把同一层内部原本逐神经元、逐样本的计算统一到一次矩阵运算中。对应到代码里,常见形式就是:
Z = A @ W + BA_out = g(Z)在更高层的框架中,例如 Keras,这一层会被封装成 Dense。一个简单的网络结构可以写成:
model = tf.keras.Sequential([ tf.keras.layers.Dense(25, activation="sigmoid"), tf.keras.layers.Dense(15, activation="sigmoid"), tf.keras.layers.Dense(1, activation="sigmoid"),])这里最需要对齐的是三个对象:Dense(units=...) 对应这一层的单元数,activation=... 对应这一层的激活函数,而多层 Dense 的串联则对应前面写成 的层级结构。
ANI、AGI 以及表征的可学习性
这一部分还引出两个常见缩写:ANI(Artificial Narrow Intelligence) 与 AGI(Artificial General Intelligence)。ANI 指面向特定任务的智能系统,例如图像分类、语音识别、推荐系统等;AGI 则指更广义的通用智能,即能够在更广范围内表现出类似人类的学习与适应能力。就当前机器学习与深度学习的发展来看,大多数成功案例仍然属于 ANI。
围绕这个话题,还会延伸出 one learning algorithm hypothesis 这类观点:不同感官皮层虽然承担的任务不同,但底层学习机制可能具有某种共性。配合感官替代与神经可塑性的例子,这里真正值得保留下来的不是对 AGI 下结论,而是另一个更贴近当前内容的判断——很多能力依赖于可学习的表征(representation),而不是预先写死的规则系统。前面神经网络各层逐步形成中间表示的过程,也可以放在这个视角下理解。
训练 TensorFlow
前面已经把神经网络的基本结构固定下来:输入写作 ,各层通过线性组合与激活函数得到新的激活向量,最后由输出层给出预测。
在实现上,网络通常仍然按层来定义。Dense(units=...) 指定这一层的单元数,activation=... 指定这一层采用的激活函数,而 compile(...) 里的 loss 对应训练时最小化的目标函数。训练接口通常写成 fit(X, y, epochs=...),它做的是在已有训练数据上不断更新参数,使 loss 逐步下降。
如果任务是二分类,损失函数通常对应 BinaryCrossentropy;如果任务是回归,则常见写法是 MeanSquaredError。这与前面已经建立起来的监督学习框架是连在一起的:模型负责给出预测,loss 负责衡量预测与真实标签之间的差异,训练过程则负责调整参数。不同之处在于,这里模型已经不再是单个线性或逻辑回归函数,而是多层网络;梯度的计算也不再手写,而是由反向传播(backpropagation)和框架自动完成。
实际实现中,更容易混淆的地方通常不在单行语法,而在层与层之间能否正确衔接。因此这里更值得优先核对的是层的顺序、units 数量、激活函数与 loss 的对应关系,以及输入输出张量的 shape 是否一致。
激活函数的选择
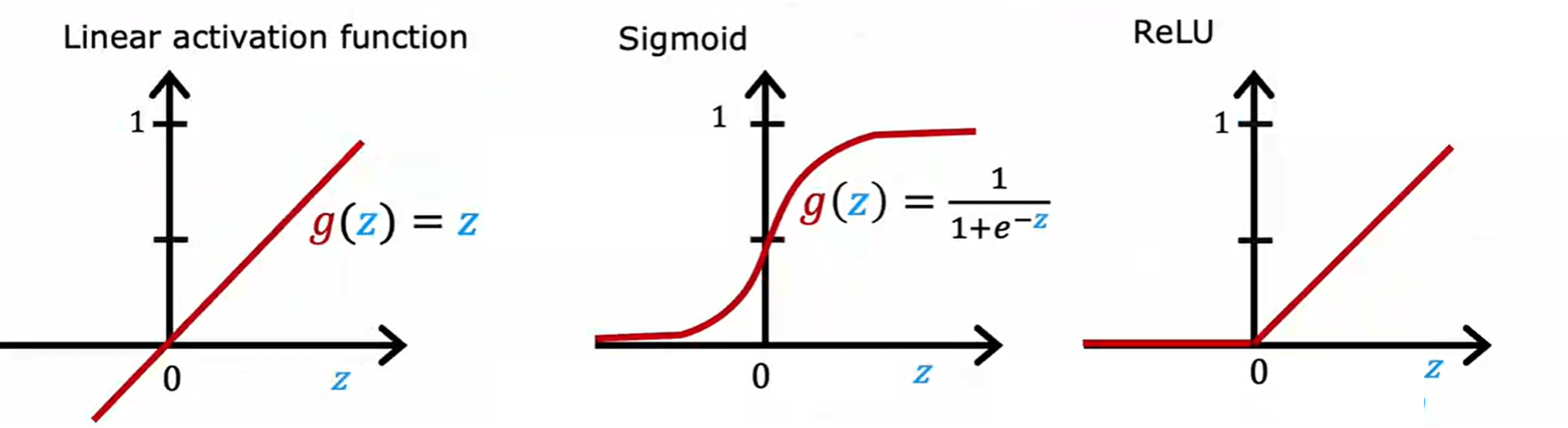
神经网络并不只使用 sigmoid。进入多层网络之后,激活函数的选择开始与层所在的位置联系起来,而不再是全网统一采用同一种函数。
除了前面已经出现过的 sigmoid,这里还会引入两种常见形式。线性激活函数(linear activation)写作
ReLU(Rectified Linear Unit)写作
这两个式子的作用需要分别看。 表示输出保持线性部分的原值,不再额外做压缩; 表示当 时输出 0,当 时直接输出 。因此,激活函数的选择最终会影响这一层输出的数值范围与表达形式。
在输出层,激活函数通常由任务类型决定。若输出是二分类概率,则仍然使用 sigmoid;若输出是一般回归值,并且既可能为正也可能为负,则更自然地使用 linear activation;若输出要求非负,则 ReLU 也可以作为输出层的候选形式。
隐藏层的情况不同。隐藏层并不直接承担概率解释或数值范围限制,它更接近中间表示的生成,因此最常见的默认选择是 ReLU。到这里,激活函数的安排已经变成按层分工处理:输出层由任务决定,隐藏层则通常采用非线性的 ReLU。
为什么隐藏层需要非线性激活函数
这一点是神经网络区别于线性模型的关键。如果所有层都只使用线性激活函数,那么无论把网络叠得多深,整体上都可以整理成一个线性变换。
例如若某层使用 ,那么它的输出就等于该层的线性部分。若两层都保持线性,则有
第二个式子已经把两层串联后的结果完全写了出来。新的权重矩阵变成 ,新的偏置变成 ,形式仍然是线性映射加偏置。也就是说,层数增加之后,函数形式并没有跳出线性模型的范围。
因此,隐藏层中的非线性激活函数不是附属细节,而是网络能够表示更复杂函数的前提。输出层是否线性,要看任务本身;但如果隐藏层全部线性化,多层结构就很难带来新的表达能力。这也是隐藏层通常优先使用 ReLU 的原因。
多类分类与 Softmax 输出
二分类中,输出层通常只需要给出一个概率;当目标变量可以取多个类别时,输出层就需要同时给出各类别的概率分布。若标签集合写作
则输出层对应一个长度为 的向量
其中第 个分量 表示输入属于第 类的概率,并满足
为了得到这组概率,需要先为每个类别计算一个线性项:
这里的 可以理解为第 类在输出层上的原始打分。softmax 的作用,是把这些打分统一变成一组和为 1 的概率:
放到神经网络里看,变化主要集中在输出层:隐藏层仍然负责形成中间表示,最后一层则把这些表示映射成多个类别的概率。若任务有 10 个类别,那么输出层就对应 10 个单元;若任务有 个类别,则输出层就对应 个单元。
多类分类中的损失函数仍然沿用交叉熵的思路。若真实标签是第 类,则单个样本的损失可以写成
这个式子只取用了输出向量里的一个分量,也就是当前真实类别对应的那一项概率。模型给真实类别分配的概率越高,这个损失值就越小。
logits 与实现中的写法
softmax 是最直接的数学表达,但在实现中,输出层常常先保留线性输出,也就是 logits。它对应的正是 softmax 之前那一组 。因此,若最后一层写成 activation="linear",输出的并不是概率,而是类别打分。
多类分类里常见的写法是:
Dense(units=N, activation="linear")SparseCategoricalCrossentropy(from_logits=True)
这里 from_logits=True 的含义很明确:损失函数接收到的是还没有经过 softmax 的线性输出,所以它会在内部按 logits 的形式完成后续计算。二分类中也有同样的对应关系:输出层先给出一个 logit,再由 BinaryCrossentropy(from_logits=True) 处理。
因此,这里需要区分两个对象:
- probabilities:softmax 之后的输出;
- logits:softmax 之前的线性输出。
前者更适合解释预测结果,后者更常直接出现在实现接口中。
多类分类与多标签分类
多类分类(multiclass classification)与多标签分类(multi-label classification)需要明确区分。
多类分类表示:一个样本只属于多个类别中的一个,因此输出层更适合写成 softmax,所有输出构成一个总和为 1 的概率分布。
多标签分类表示:一个样本可以同时满足多个标签,因此标签不再是单个类别,而是一个向量,例如
这个向量里的每个分量都对应一个独立判断,因此输出层中的各单元之间不要求和为 1。结构上,它更接近多个并行的二分类输出,常见做法就是让每个输出单元各自配一个 sigmoid。
写成网络结构时,二者的区别主要落在最后一层:
- multiclass:一个 softmax 输出层,对应一个类别分布;
- multi-label:多个独立输出单元,对应多个并行的二分类判断。
输出层的设计一旦分清,前面的隐藏层结构并不需要因此重写;真正变化的是最后一层的激活形式,以及与之匹配的标签表示方式。
多类输出网络的实现补充
在多类分类任务中,网络结构通常可以写成隐藏层加多类输出层的形式。隐藏层继续使用前面已经固定下来的激活函数选择,输出层则根据类别数设置单元数量。若采用 softmax 的显式写法,最后一层可写成 Dense(units=N, activation="softmax");若采用 logits 写法,则写成 Dense(units=N, activation="linear"),并在 loss 中指定 from_logits=True。
因此,从二分类推进到多类分类时,真正需要改动的部分主要集中在三项:输出层单元数、输出层激活形式,以及与之匹配的损失函数。前面的层级记号、前向传播结构和张量 shape 的理解方式都保持不变。
模型评估与诊断
模型进入训练阶段之后,首先需要固定的不是继续改结构,而是评估当前问题究竟出在哪里。这里最基本的分工是:训练集用于拟合参数,交叉验证集用于做模型选择和超参数选择,测试集只用于最后估计泛化误差。如果在选择模型时反复查看测试集表现,那么测试误差本身也会变得过于乐观。
沿着这条分工,误差记号自然分成三项:、 与 。前两者主要用于诊断,最后一项才用于汇报最终表现。

偏差与方差的判断可以先从最常见的几种情形入手:
- 高偏差(underfit): 较高,且
- 高方差(overfit): 较低,但
- 偏差和方差同时存在: 偏高,同时 明显更高
只看训练误差和交叉验证误差还不够,很多时候还需要再引入一个表现基准。这个基准可以是 human-level performance、已有算法表现,或者结合经验给出的合理误差水平。把当前模型放到这个基准旁边之后,才能更清楚地区分:训练集上是否已经学好,以及问题是否主要落在泛化这一侧。
正则化参数 也需要放在这个诊断框架里理解。 过大时,模型更容易走向高偏差; 过小时,模型更容易走向高方差。因此, 需要在训练集上拟合、在交叉验证集上比较,再选出对应 更合适的取值。对神经网络也是类似的思路:网络规模、正则化强度和数据量通常要一起看,而不是单独看某一个因素。

学习曲线把这种诊断再往前推进了一步。若随着训练集规模增加, 与 都停在一个较高位置附近,那么问题更接近高偏差;若 已经较低,而 仍明显偏高,则更接近高方差。由此再决定下一步动作会更直接:高偏差通常更需要模型表达能力、特征或更小的正则化;高方差则更可能从更多数据、适度更强的正则化或更合适的特征集合中获益。
放到神经网络里,这组判断还会带来一个额外变化:较大的网络常常具有较低偏差。如果训练集上表现还不够好,那么先考虑更大的网络往往是自然的方向;如果训练集表现已经不错,但交叉验证集表现明显落后,则问题更多会落在泛化这一侧。
误差分析、数据与迁移学习
当对高偏差还是高方差已经有了初步判断之后,下一步通常不是立刻大范围改模型,而是先看错误究竟集中在哪里。误差分析的做法很直接:从交叉验证集里抽取一批错误样本,按共同特征分类统计,看哪些类型最值得优先处理。这样整理错误,不只是为了描述现象,更是为了给后续改进排序。
以文本分类这类任务为例,错误可能集中在特殊词形、刻意拼写变形、特定路由特征、图片内嵌内容等不同来源。如果某一类错误占比明显更高,那么下一步更可能围绕这类错误补特征、补数据或改标注,而不必同时做很多彼此无关的尝试。误差分析一旦做细,调试模型就会从盲目试错转向有针对性的迭代。
在数据层面,常见的改进包括三类。第一类是真实收集更多数据;第二类是 data augmentation,也就是在现有样本基础上构造新的训练样本;第三类是 synthetic data 与 transfer learning。它们都与扩大数据有关,但侧重点并不一样。
data augmentation 的关键在于,引入的变化应当代表测试环境中真的会出现的扰动。图像中的形变、位移、轻微遮挡,语音中的背景噪声、通话质量变化,都属于比较典型的情形;纯随机、没有实际分布含义的噪声则未必有效。这里真正需要对齐的是训练数据与部署场景中的扰动结构。
transfer learning 则更进一步:如果当前任务的数据较少,但输入类型与另一个大规模任务一致,就可以先利用在大数据集上学到的参数,再在自己的数据上继续 fine-tune。图像任务里,前几层常常已经学到了边缘、角点、曲线等相对通用的表示,因此这些参数不一定需要每次都从头训练。实际使用时,可以只训练新的输出层,也可以继续训练全部参数,具体要看数据规模与任务差异。

模型开发放到这里看,会呈现出比较清楚的循环:先定结构,再训练,再做诊断与误差分析,随后根据结果去改数据、改特征、改正则化或改结构。
从训练到部署:项目闭环与风险约束
模型训练完成并不意味着项目结束。一个完整的机器学习系统通常还要经历:确定问题范围、定义与收集数据、训练模型、部署到生产环境,再通过监控和维护继续迭代。部署之后,很多原本在 notebook 里不显眼的问题都会变得具体起来,例如推理服务如何调用、日志如何记录、模型如何更新、线上表现如何监控,这些通常都属于更大的工程问题。
这里还会自然碰到另一组约束:能训练出来的系统,并不一定都适合直接上线。生成虚假内容、欺诈对抗、有害内容扩散、对脆弱群体的潜在伤害,都属于模型部署前后必须认真考虑的问题。更实际的做法通常包括:在项目早期就讨论可能出错的使用场景;部署前进行系统审计;查阅所在行业已有标准;如果存在潜在伤害,再提前准备缓解方案,并在部署后持续监控。
这部分内容没有引入新的模型公式,但它把前面的模型训练放进了一个更完整的工程闭环里:模型性能只是系统的一部分,数据、部署环境、监控与风险控制同样属于整体设计。
倾斜数据集、Precision 与 Recall
分类任务里,accuracy 并不总是可靠指标。一个最典型的情形是类别极不平衡:如果正类非常少,那么一个几乎总是预测负类的模型,也可能得到很高的准确率,但它并没有真正解决问题。
这时更有区分力的指标通常是 precision 和 recall。若把正类记为 ,并把混淆矩阵中的 true positive、false positive、false negative 记作 ,则
precision 衡量的是:模型判为正类的样本中,有多少是真的正类;recall 衡量的是:真实正类中,有多少被模型成功找出来。这两个式子的分母不同,因此它们关注的方向也不同。precision 的分母是所有被预测为正的样本,recall 的分母则是所有真实为正的样本。
如果把二分类输出写成一个概率分数,那么一般形式可以记为:当
时预测为正类。阈值提得更高,模型往往会更谨慎,precision 更容易上升,而 recall 往往下降;阈值放得更低,则更容易把正类都找出来,但误报也会更多。precision 与 recall 因而需要放在具体任务目标里一起看,而不是孤立比较。

当需要把 precision 与 recall 合并成一个紧凑指标时,常用的是 F1 score:
其中 表示 precision, 表示 recall。它是二者的调和平均,因此当其中一项明显偏低时, 不会被另一项的高数值轻易抬高。这使得 F1 比简单平均更适合比较那些 precision 与 recall 差异很大的模型。
到这里,模型评估已经不再只是一个单独的误差值,而是与数据分布、任务目标、阈值选择以及系统部署背景一起构成了一套更完整的判断框架。
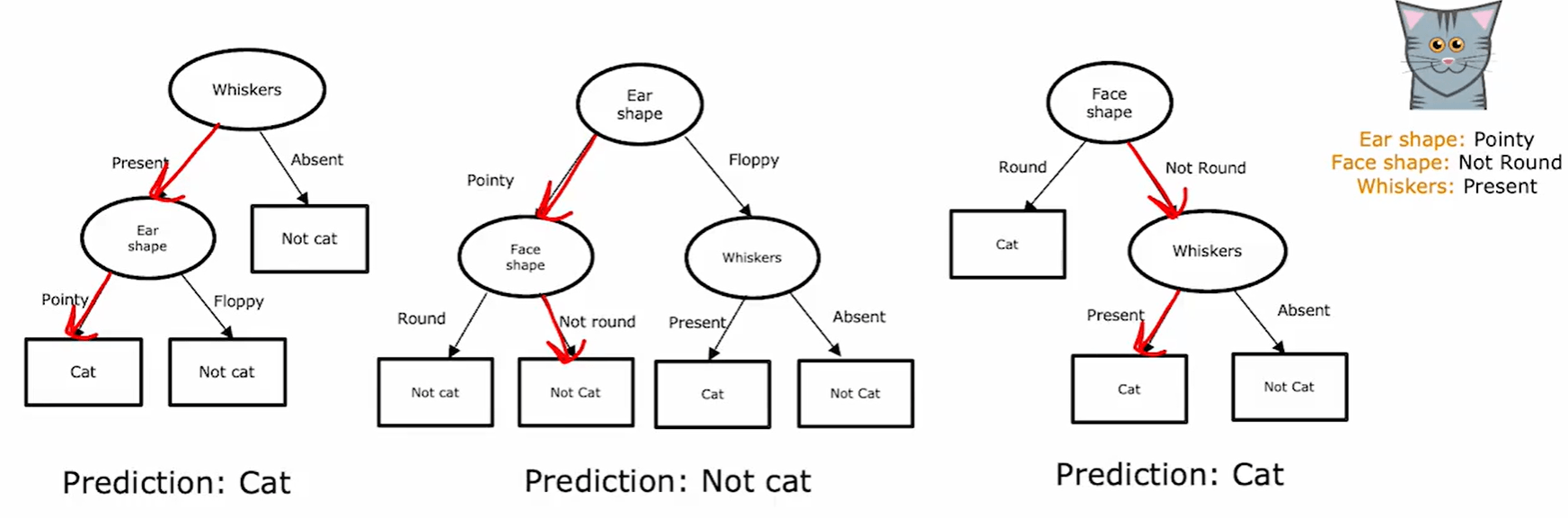
决策树
神经网络把输入逐层映射到输出,决策树则沿着另一条路径组织预测。对一个样本来说,模型先检查某个特征,再按照判断结果进入不同分支;重复几次之后,就会停在某个叶节点上。分类任务里,叶节点给出类别;回归任务里,叶节点给出数值。
如果把输入空间看成被不断切开的区域,那么树的每一次分裂都在把原来的区域继续细分。根节点负责第一次切分,内部节点继续缩小范围,叶节点则对应某一块已经不再继续分裂的区域。于是,决策树学到的函数通常是分段的:同一片区域里的样本共享同一个输出。
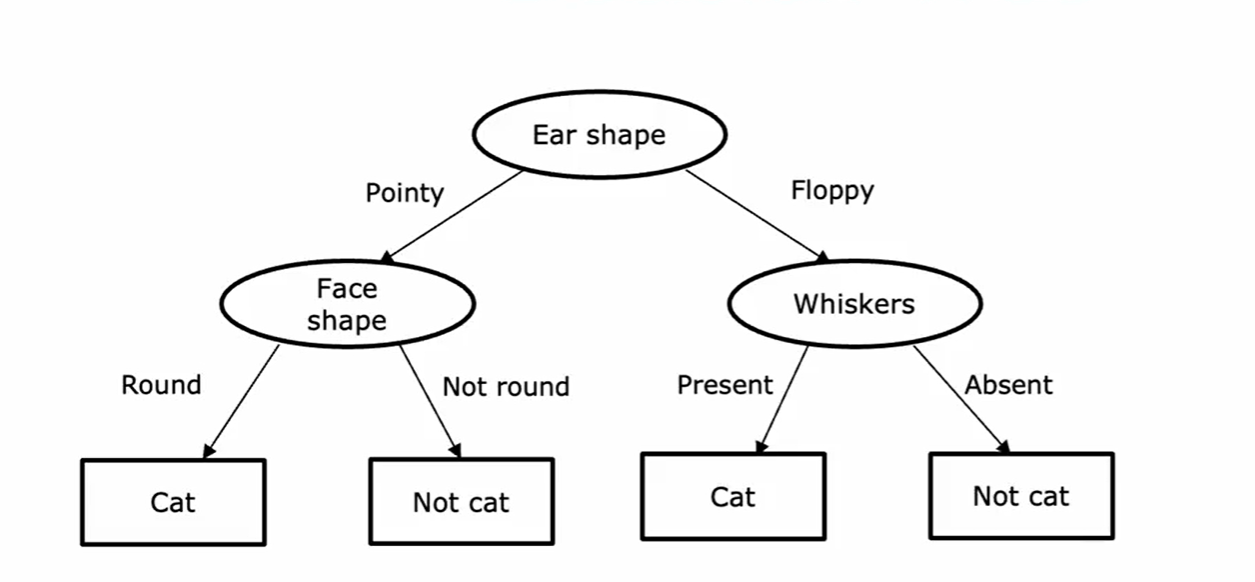
训练过程也正是围绕这种递归切分展开的。全部样本先落在根节点,当前节点上再从候选特征中挑出一个分裂方式,把样本切成几个子集;对子节点重复同样的操作,直到满足停止条件。常见的停止条件包括:节点已经足够纯、树深达到上限、继续分裂带来的改善太小,或者当前节点样本数已经很少。沿着这条思路看,决策树的学习过程非常集中:每一步都在回答当前节点该如何继续分裂。
纯度、熵与信息增益
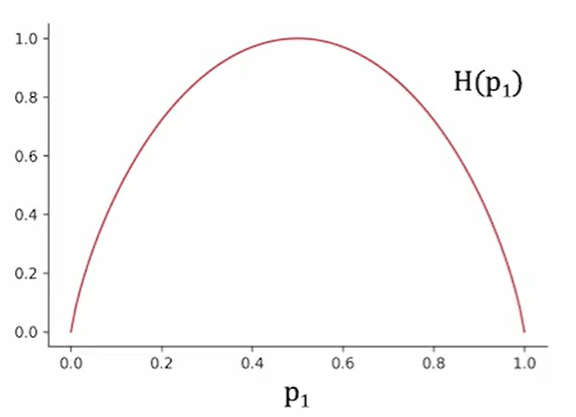
树要长出来的关键在于用哪个特征分裂。如果一次分裂之后,子节点里的样本类别明显更单一,那么这次分裂就更值得保留。于是,问题自然落到对节点纯度的度量上。
在二分类情形里,若某个节点中正类比例为 ,常见的 impurity 度量是熵:
这个式子描述的是节点内部的混杂程度。当 或 时,节点里已经只剩一种类别,因此熵为 0;当两类样本各占一半时,熵达到最大。也就是说,熵越大,节点越混杂;熵越小,节点越接近单一类别。
有了纯度的刻画之后,分裂标准就可以写得很明确。设父节点样本数为 ,左右子节点样本数分别为 ,则一次分裂带来的信息增益写作
这里 是父节点的熵, 是左右子节点的熵。括号里的加权平均,表示分裂之后整体还剩多少混杂程度;父节点熵减去这部分,就得到这次分裂真正带来的改善。信息增益越大,当前特征越适合作为这个节点的分裂依据。
写成算法语言,每个节点都会枚举候选特征,分别计算对应的信息增益,再把当前增益最大的那一种留下来。于是,树的生长顺序不是人为指定的,而是由局部最优分裂一步步决定出来的。
类别变量、连续变量与回归树
二值特征只是最简单的起点。若某个类别特征有多个可能取值,树仍然可以直接围绕这些取值继续分裂;从表示上看,节点不一定只有左右两支,也可以长出更多分支。与此同时,类别变量在很多数值模型里还会转换成独热编码(one-hot encoding):若一个特征有 个类别,就把它改写成 个 0/1 分量,每一维对应一个类别是否出现。这样的表示对线性模型和神经网络尤其自然,因为它把离散类别转成了可直接参与数值计算的向量。
连续变量则把分裂问题带到了另一种形式。对于连续特征 ,节点里的判断通常写成
其中 是某个候选阈值。训练时会尝试若干可能的切分点,并比较它们带来的纯度改善,最终留下当前节点上更合适的那个阈值。树面对连续变量时,仍然是在做局部区域划分,只是分裂条件从类别取值变成了阈值比较。
当输出 变成实数时,分类树就自然过渡到回归树。此时叶节点不再输出类别,而是输出一个数值预测;常见做法是令叶节点输出该节点中训练样本目标值的平均值。分裂标准也随之从分类纯度切换到回归误差下降。若把当前节点的平方误差记为
其中 表示该节点中目标值的平均数,那么回归树每做一次分裂,本质上都在比较这类误差是否明显下降。于是,分类树与回归树在结构上几乎一致,真正变化的是叶节点输出的含义,以及当前节点够不够纯的判断方式。
多个决策树
单棵树直观,但也很敏感。训练集里只要换掉少量样本,或者样本分布稍有波动,整棵树的结构都可能变掉。模型的不稳定性,正是树集成出现的直接背景。
最基础的集成方法是 bagging。设原训练集大小为 ,就从中进行 次有放回抽样,得到一个 bootstrap 数据集 ;重复这一过程,又会得到 。每个 bootstrap 数据集都训练出一棵树,最终再把多棵树的输出做投票或平均。对分类问题,这通常写成多数投票;对回归问题,则更常写成均值:
这里 表示第 棵树, 表示树的总数。这个式子表达得很直接:每棵树先给一个预测,最后再做平均。
随机森林在 bagging 的基础上又加了一层随机化:每个节点分裂时,并不是从全部特征中找最优切分,而只从一个随机抽取的特征子集中选择。这样做之后,各棵树之间的相关性会进一步下降,集成效果往往也更稳。
XGBoost 则沿着另一条路线展开。它不会把多棵相互独立的树简单平均,而是让后续树逐步去修正前一轮模型尚未处理好的部分。前面的树先给出一个当前预测,后面的树再围绕残差继续拟合,因此整个模型是逐步累加起来的。这也使树集成内部形成了两种很不一样的组织方式:随机森林更接近并行平均,boosting 更接近顺序修正。
树模型在监督学习中的位置
把这一部分接到前面的内容后,Part 2 里已经摆出了两套很不同的监督学习工具。神经网络通过连续参数和层级表示去构造预测函数,决策树则通过区域切分与节点规则来组织输出。两类模型面对的是同一类监督学习任务,但它们处理输入、形成表示、控制复杂度的方式并不相同。
如果数据是表格型、结构化的,树模型往往会成为非常自然的候选,尤其是随机森林和 XGBoost 这类树集成,经常能给出稳定的强基线。若输入本身就是图像、音频或文本,前面整篇笔记围绕的神经网络则通常更有延展性。这样看下来,监督学习这一部分到这里才真正接近完整:线性模型、神经网络和树模型并列放在一起后,模型之间的边界感会清楚很多,后面再进入没有显式标签的非监督学习,视角也会转得更自然一些。
结语
回头看这一部分,监督学习内部的轮廓已经比一开始清楚得多了。前面大量内容都在围绕参数、损失函数、梯度下降、输出层和泛化误差展开;到了这里,决策树与树集成又补上了另一种组织预测的方式。放在一起看,更容易体会到机器学习里真正稳定的部分并不是某一个具体模型,而是那几件始终反复出现的事:怎样表示输入,怎样定义目标,怎样控制复杂度,怎样判断泛化能力。
接下来的内容若转向非监督学习,问题本身也会换一种形态。标签不再提前给定,模型面对的将不再是输入对应什么输出,而是数据本身有什么结构。前面已经建立起来的许多判断习惯——怎样看特征、怎样理解表示、怎样区分模型表达与泛化——到那里并不会失效,只是会从有监督的框架里继续往外延伸。