本文是我学习吴恩达(Andrew Ng)《Machine Learning Specialization》(2022)后整理的笔记,记录 Unsupervised Learning, Recommenders and Reinforcement Learning 这一部分。
无监督学习
无标签数据与结构
无监督学习处理的是没有显式标签的数据。训练集中只有输入样本,通常没有对应的目标值 。因此,模型的任务不再是拟合一个从 到 的预测函数,而是从样本自身的分布中找出结构。
这类结构主要有两种典型形式。若样本在空间中自然形成若干组,问题就会转向聚类;若大多数样本呈现相近模式,少数样本明显偏离主体分布,问题就会转向异常检测。前者关注样本之间的相似性,后者关注样本相对正常模式的偏离程度。
聚类
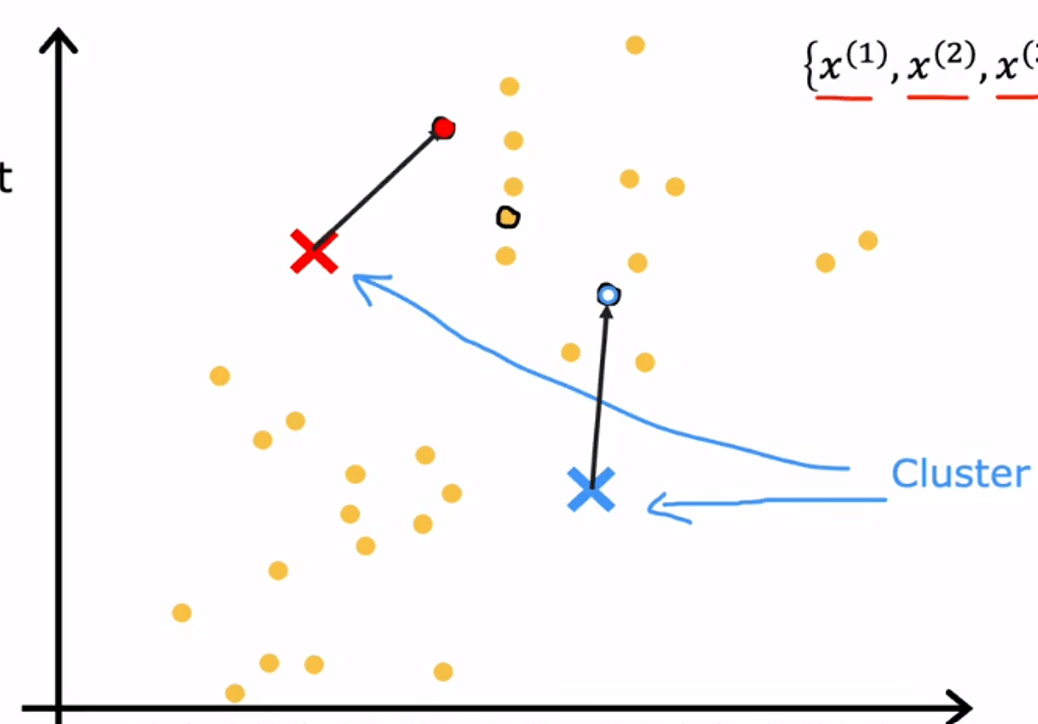
聚类的目标是把没有标签的样本划分成若干簇。K-means 是这一部分最基础的算法。它先设定簇的个数 ,并为每个簇维护一个中心点 。算法在两步之间反复交替:
- 将每个样本分配给距离最近的中心点;
- 根据当前分配结果,重新计算每个簇的中心点。
若第 个样本记为 ,第 个聚类中心记为 ,第 个样本所属簇编号记为 ,则 K-means 的目标函数为
其中 是样本 所属簇的中心。二范数平方表示样本到该中心的距离平方,整体求和后再除以样本数 ,得到平均组内偏离程度。K-means 的分配步骤和更新步骤,都是围绕降低这个目标函数进行的。
初始化会影响 K-means 的结果。不同初始中心点可能使算法收敛到不同结果,因此常见做法是多次随机初始化,再保留目标函数值较小的一次。聚类数 的选择也没有唯一公式,通常结合代价函数曲线、数据结构和任务解释来决定。若 太小,多个簇会被合并;若 太大,模型会把原本连续的结构切得过细。
异常检测
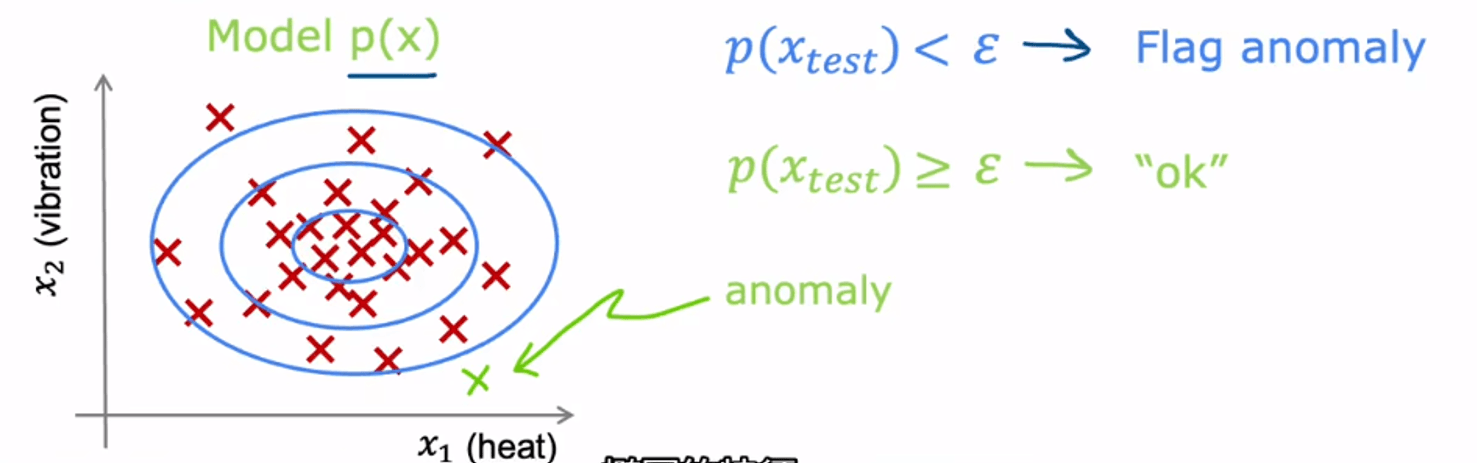
异常检测的目标是识别偏离正常模式的样本。它不要求把所有样本划分成多个簇,而是先刻画正常样本的分布,再根据概率密度判断新样本是否异常。
单个特征常用高斯分布建模。若特征 的均值为 ,方差为 ,则概率密度函数为
这里 决定分布中心, 决定分布宽度。若 离均值较远,指数项会下降,对应概率密度较小。异常检测正是利用这一点,将低概率样本视为可疑点。
若一个样本包含 个特征,并先采用特征近似独立的建模方式,则整体概率写成
其中 是第 个特征, 和 分别由训练数据估计得到。判定规则为
当样本概率小于阈值 时,预测为 anomaly。阈值通常通过交叉验证集调节,而不是直接凭直觉指定。
异常检测和监督学习分类的分界,主要取决于异常样本的数量与类型。如果异常样本很少,且未来可能出现未见过的新异常,异常检测更合适;如果正负样本都比较充足,且异常类型相对固定,监督学习分类更自然。特征选择同样关键。一个特征若无法区分正常和异常,放进概率模型后也不会带来有效判断;好的特征应能让异常样本在分布中落到低概率区域。
推荐系统
评分矩阵与预测形式
推荐系统的数据通常由用户、项目和交互记录组成。若用矩阵表示,行可对应项目,列可对应用户,矩阵元素是评分、点击、收藏或其他反馈。这个矩阵往往很稀疏,因为每个用户只接触过项目集合中的一小部分。
若用户 对项目 的真实评分记为 ,是否存在反馈用 表示,则 表示这个位置有观测数据。推荐模型只应在 的位置上计算误差,未观测位置不能直接当作负样本处理。
若项目特征向量为 ,用户参数向量为 ,用户偏置为 ,预测评分为
这里 表示项目在特征空间中的位置, 表示用户在同一特征空间中的偏好方向,内积给出项目和用户之间的匹配分数,偏置项 用于表示用户整体评分倾向。
协同过滤
协同过滤的核心在于同时学习项目特征和用户参数。项目特征 不再完全依赖人工指定,而是从用户评分矩阵中学习出来;用户参数 也在同一目标函数中一起优化。
常见代价函数为
第一项只在有评分的位置上计算预测误差。第二项是正则化项,约束用户参数和项目特征的规模,减少参数过大带来的不稳定。这个公式说明推荐系统的训练对象不是普通样本表,而是稀疏的用户项目交互矩阵。
反馈标签也可以是二值形式。收藏、点赞、点击都可以作为 binary labels,用 0 或 1 记录用户是否产生某种行为。此时预测目标从评分值变为偏好概率或点击概率,损失函数也会随任务形式调整。
均值归一化用于处理不同项目整体评分水平的差异。若项目 的平均评分是 ,归一化标签可以写成
模型先学习用户相对该项目平均评分的偏离,预测时再把均值加回去。这样可以避免模型过多地学习项目整体受欢迎程度,而忽略用户个体差异。
在 TensorFlow 中,协同过滤通常把用户参数矩阵和项目特征矩阵设为可训练变量,再用自动微分最小化上面的代价函数。实现中最容易出错的是维度:项目数、用户数、特征维度必须和评分矩阵的行列对应。训练完成后,每个项目都有一个向量表示,因此可以通过向量距离寻找相似项目。
基于内容的过滤
协同过滤主要依赖用户项目交互。基于内容的过滤把项目本身的内容特征放进模型,例如类型、关键词、文本描述、价格区间或其他结构化属性。用户也可以由历史行为、画像特征或上下文特征表示。两类方法的差别主要在输入来源:协同过滤更依赖交互矩阵,基于内容的过滤更依赖用户和项目自身特征。
引入深度学习后,用户和项目可以分别经过神经网络映射到同一个向量空间。若用户网络输出 ,项目网络输出 ,推荐分数可写成
其中 和 是同维向量。内积越大,表示二者在该表示空间中越接近,推荐分数也越高。这一形式和协同过滤中的内积预测相似,但向量不再只是直接训练出的自由参数,而是由输入特征经过网络得到。
当项目目录很大时,推荐系统还需要处理检索问题。对每个用户遍历所有项目再排序代价很高,因此通常先召回候选集合,再对候选项目做精排。建模和检索在这里开始同时出现,推荐系统不只是一个评分预测模型,也是一套需要在大规模项目库上运行的系统。
推荐系统的边界
推荐系统会持续影响用户看到什么、点击什么和停留多久。模型输出会改变用户行为,新的用户行为又会反过来成为后续训练数据。这样的反馈循环使目标函数的选择变得很敏感。
若训练目标只围绕 clicks、likes 或 watch time 展开,系统可能持续强化高反馈内容,而不一定符合用户长期利益。推荐系统的目标设计、反馈信号选择和上线后的监控,都直接影响系统输出方向。这里的核心不是给出一个额外公式,而是明确推荐系统的训练目标本身需要被谨慎定义。
强化学习
状态 动作 奖励
强化学习研究的是连续决策问题。主体在环境中采取动作,环境返回新的状态和奖励;下一步动作又会继续影响之后的状态。因此,它不再只处理固定数据集上的单次预测,而是关注一串动作带来的长期结果。
基本对象包括:
- state :当前状态
- action :当前状态下采取的动作
- reward :时刻 收到的即时反馈
- policy :从状态到动作的决策规则
即时奖励只描述某一步反馈,强化学习优化的是从当前时刻开始的累计回报。若从时刻 开始,return 定义为
其中 是折扣因子。 是当前奖励, 是下一步奖励折扣后的贡献, 是再下一步奖励的贡献。 越接近 1,未来奖励的影响越大; 越小,目标越偏向近期反馈。
状态动作值函数
在状态 下采取动作 后,后续如果按策略 行动,可以得到一个期望 return。这个量称为状态动作值函数,记为
其中 表示当前状态为 , 表示当前动作是 , 是从当前时刻开始的 return。上标 说明后续动作由策略 决定。
不是单步 reward。它评估的是当前动作和后续策略共同带来的长期回报。若某个动作的 值更高,表示在当前状态下先采取该动作,并在之后遵循策略 ,能够得到更高的期望 return。
Bellman 方程
Bellman 方程把长期 return 写成递归形式。对状态动作值函数,可以写成
其中 是在状态 下采取动作 得到的即时奖励, 是下一状态, 是下一状态下按照策略 选择的动作。右侧第一项是当前一步反馈,第二项是折扣后的未来价值期望。
若环境是确定性的,下一状态和下一动作可以直接确定;若环境存在随机性,就需要对可能的 和 取期望。这个方程将完整的长期回报拆成当前奖励和下一状态价值,因此是价值函数学习的基础。
最优状态动作值函数记为 。对应的 Bellman 最优方程为
这里的 表示在下一状态 中选择未来价值最大的动作。最优策略可以由最优 Q 函数得到:
这个式子表示,在状态 下选择使 最大的动作。
函数逼近
当状态和动作数量很少时,可以用表格存储每个状态动作对的 Q 值。连续状态空间中,这种表格方法不再可行。例如状态可能包含位置、速度、角度、角速度等连续量,状态组合几乎不可穷举。此时需要用函数逼近表示 Q 函数。
若用神经网络近似状态动作值函数,可以写成
其中 是网络参数。输入为状态和动作,输出为对应 Q 值估计。若动作集合离散且数量不大,也可以让网络输入状态 ,一次输出所有动作对应的 Q 值:
其中 是可选动作集合。这样可以一次前向传播得到同一状态下所有动作的价值估计。
根据 Bellman 最优方程,一步训练目标可写为
其中 是当前转移得到的奖励, 是下一状态, 表示目标网络参数。训练损失写成
这里 是当前网络对当前状态动作对的估计, 是由奖励和下一状态最大 Q 值构成的目标。训练的任务是让当前 Q 估计接近这个 Bellman 目标。
探索与稳定训练
有了 Q 值估计后,最直接的动作选择方式是选择当前 Q 值最大的动作。但强化学习中的数据由动作产生,如果一直只选择当前估计最好的动作,模型可能无法发现更优路径。探索与利用需要同时保留。
-贪婪策略给出了一种简单规则:
- 以概率 选择当前 Q 值最大的动作
- 以概率 随机选择一个动作
其中 控制探索比例。 较大时,行为更随机; 较小时,行为更依赖当前价值估计。这个机制用于在已有知识和新动作尝试之间保持平衡。
训练中还会使用 mini-batch 和 soft update。mini-batch 从经验样本中取一小批转移一起更新,减少单条样本带来的波动。soft update 用于缓慢更新目标网络参数:
其中 是当前网络参数, 是目标网络参数, 是较小的更新系数。这个式子表示目标网络只向当前网络移动一小步,而不是直接复制当前网络。目标网络变化较平滑,Bellman target 也会更稳定。
状态表示
状态表示决定了价值函数能够利用哪些信息。状态应包含影响后续决策和回报的关键变量。若状态缺少必要信息,即使 Bellman 方程和神经网络结构都写得正确,模型也难以学习稳定策略。
这一点和前面机器学习中的特征选择相通。区别在于,强化学习中的状态会影响后续动作、环境转移和长期 return,因此状态表示的质量会直接影响整条决策链。